샤딩(Sharding)
샤딩(Sharding)
샤딩(Sharding)
Database의 샤딩(Sharding)이란?#
같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법을 의미.
- 샤딩은 수평 분할(Horizontal Partitioning)과 동일.
- 테이블의 인덱스의 크기를 줄이고, 작업 동시성을 늘리기 위함.
- application level에서도 가능하지만 database level에서도 가능.
수평 분할 (horizotal partitioning, Range Based Partitioning)#
샤딩과 동일한 의미를 가지며 스키마를 다수의 복제본을 구성하고 각각의 샤드에 샤드키를 기준으로 데이터를 분리하는 것을 말한다. DBA가 데이터의 패턴과 저장공간을 잘 알고 샤드키를 선정하여 분할한다.
| id | Name | Age |
|---|---|---|
| 1 | Bob | 27 |
| 3 | Alice | 23 |
| 5 | Dennis | 20 |
| 7 | Miller | 24 |
| id | Name | Age |
|---|---|---|
| 2 | Sago | 29 |
| 4 | Riley | 30 |
| 6 | Wilson | 18 |
| 8 | Brown | 25 |
샤딩의 장점과 단점#
장점#
- 수평적 확장 horizontal scaling (=scaling out)이 가능하다: 서버의 하드웨어(RAM, CPU 등)를 업그레이드하는 수직적 확장과 다르게, 존재하는 stack에 machine을 추가하는 방식으로 능력을 향상시킬 수 있다.
- 쿼리 반응 속도를 빠르게 한다: 스캔 범위를 줄이기 때문!
- application을 신뢰할 수 있게 만든다: 서버 다운 등 생겼을 때, un-sharded 데이터베이스와 다르게 단일 shard에만 영향을 줄 확률이 높다. application이 일부라도 작동할 수 있도록 위험을 완화시켜준다.
단점#
- 잘못 사용했을 때 risk(데이터 손상, 유실 등)가 크다.
- 데이터가 한 쪽 shards에 쏠려 sharding이 무의미 해질 수 있다.
- 한 번 쪼개게 되면, 다시 un-sharded 구조로 돌리기 어렵다.
- 모든 데이터베이스 엔진에서 natively support 되지 않는다.
샤딩시 고려사항#
- 데이터 재분배
- 샤딩을 진행 한 DB의 물리적인 용량한계와 성능한계가 왔을 경우 적절하게 shard수를 scale-up 작업을 늘릴 수 있도록 설계해야한다. (확장고려)
- 샤딩으로부터 데이터 조인
- 샤딩된 데이터베이스간에 조인이 불가능하기 때문에 어느정도의 데이터 중복은 감안해야 한다.
- 파티셔닝 잘 구현하기
- 샤딩의 기준이되는 샤드키를 잘 정하거나 hash의 경우 함수를 잘 선택해야 한다.
- 샤드된 DBMS들의 트랜잭션 문제
- XA와 같은 Global Transaction을 사용하면 샤딩된 데이터베이스간에 트랜잭션이 가능하나 성능저하의 문제가 있다.
- Global Unique Key
- 샤딩에 경우 DBMS에서 제공하는 auto-increment를 사용하면 key가 중복될 가능성이 있기 때문에 application 레벨에서 key 생성을 담당해야 한다.
- 데이터 축소
- Table 단위를 가능한 작게 만들자.
샤딩(Sharding) 구성시 고려할 문제#
- 샤딩 알고리즘 : 정수값 등으로 샤딩을 처리할 때 데이터의 비율 고려
- 샤딩 데이터 조회 : 분산된 Database에서 Data를 어떻게 읽을 것인가
- 데이터 재분배 : 서비스 정지 없이 데이터베이스 스키마 및 서버 설계 필요
- 샤딩 조인 : 역정규화를 어느정도 감수해야 함
샤딩(Sharding) 방법#
Shard Key를 어떻게 정의하느냐에 따라 데이터를 분산시키는 방법이 결정됩니다.
range-based sharding#
주어진 value의 범위를 기반으로 데이터를 나누는 샤딩 방법입니다. 예를 들어 연도 컬럼을 이용하여 데이터를 나눌수 있습니다. 이 방식을 이용하면 몇몇 개의 shard를 만들고 범위에 연도에 따라 데이터를 저장할 수 있습니다.
| hiredate | Name | Age |
|---|---|---|
| 1981 | Bob | 27 |
| 1982 | Alice | 23 |
| 1983 | Dennis | 20 |
| 1985 | Miller | 24 |
| hiredate | Name | Age |
|---|---|---|
| 2001 | Sago | 29 |
| 2005 | Riley | 30 |
| 2007 | Wilson | 18 |
| 2009 | Brown | 25 |
| hiredate | Name | Age |
|---|---|---|
| 2011 | Oh | 32 |
| 2012 | Kim | 33 |
| 2017 | Park | 24 |
| 2021 | Lee | 42 |
장점#
가장 큰 장점은 실행이 비교적 간단하다는 것이다. 모든 shard들은 다른 데이터를 가지고 있고, original 데이터베이스 뿐 아니라 서로가 똑같은 스키마를 가지게 된다. application code는 그저 데이터가 어떤 범위인지 읽고 그에 상응하는 shard에 쓰면 된다.
단점#
반면, 데이터베이스를 골고루 분배하지는 못하기 때문에 앞서 말한 데이터베이스 hotspots가 생길 수 있다. 위 그림 상으로는 모든 shard들이 같은 양의 데이터를 가지고 있지만, 특정 데이터가 다른 데이터에 비해 더 많이 찾아질 수 있기 때문에 읽는 횟수가 불균형할 수 있다.
hash based sharding#
다른 말로 Key Based Sharding, modulus-based sharding이라고도 불린다. 키와 같은 값을 해쉬함수(Hash)에 넣어 나오는 값으로 서버를 지정하는 방식
hash 함수는 고객 이메일과 같은 데이터 조각을 Input으로 받아, hash value라는 완전히 다른 형태의 value를 Ouput으로 내보낸다. sharding의 관점에서 봤을 때 hash value는 들어오는 데이터가 저장될 shard를 결정하는 shard ID가 될 것이다.
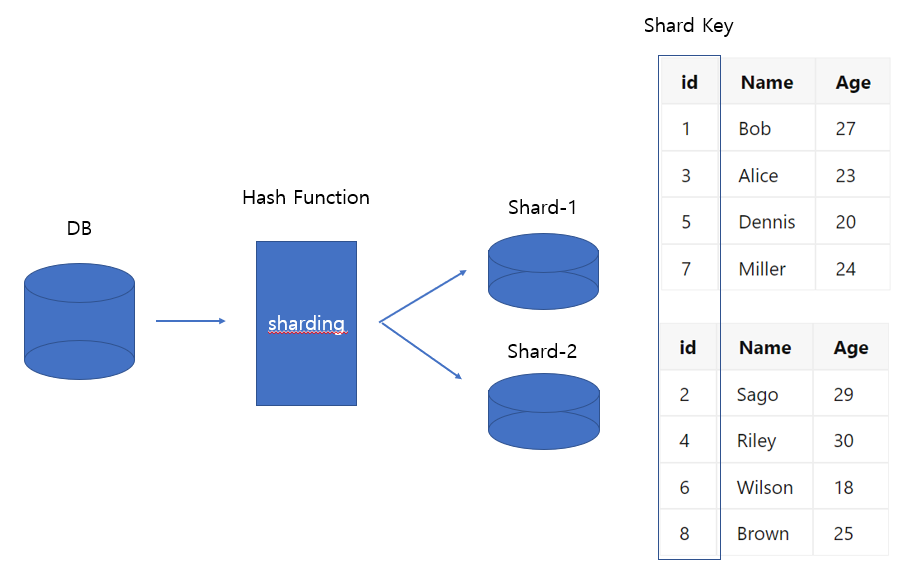
shard key#
올바른 shard에 일관성 있는 방식으로 들어갈 수 있도록 entry를 위치시키기 위해, hash 함수에 들어가는 value들은 같은 column에서 나와야 한다. 이 colum을 shard key라고 부른다.
- 각 행을 위한 고유 식별자를 생성한다는 측면에서 shard keys는 primary keys(pk)와 비슷하다.
- 넓게 본다면, shard key는 정적이어야 하고 시간에 따라 바뀌어서는 안 된다. 그렇지 않으면 업데이트에 필요한 작업이 증가하고 퍼포먼스를 느리게할 수 있다.
단점#
key based sharding이 많이 쓰이긴 하지만, 데이터베이스에 서버를 동적으로 추가하거나 제거할 때 어려울 수 있다. 서버를 추가할 때 각각의 서버는 그에 상응하는 hash value가 있어야 하고, 존재하는 많은 entry들은 맞는 hash value에 다시 매핑되고, 적합한 서버에 migrate 되어야 한다. 데이터를 rebalancing하는 것을 시작한다면 새로운 hash 함수 뿐 아니라 예전 hsah 함수도 유효하지 않게 된다. 결과적으로 migration을 하는 동안 애플리케이션은 새로운 데이터를 쓰지 못하고, 쉴 수밖에 없다.
장점#
이 전략의 가장 큰 장점은 hotspots를 방지하기 위해 데이터를 골고루 분배할 수 있고, 알고리즘적으로 분배하기 때문에 range나 directory와 다르게 모든 데이터가 어디에 위치하는지 말해주는 map을 가질 필요가 없다.
Directory Based Sharding#
파티셔닝 매커니즘을 제공하는 추상화된 서비스 생성.
이 sharding을 실행하기 위해서는 반드시 어떤 shard가 어떤 데이터를 갖고 있는지를 추적할 수 있는 shard key를 사용하는 lookup table을 만들고 유지해야 한다.
lookup table#
간단히 말하면 특정 데이터를 찾을 수 있는(where specific data can be found) 정적인 정보를 갖고 있는 테이블이다.
Delivery Zone 열은 shard key로 정의된다. shard key로부터 온 데이터는 각각의 행이 어떤 shard에 쓰여져야 하는지를 lookup 테이블과 함께 쓰여진다. range based sharding과 비슷해 보이지만, 범위를 기준으로 shard key의 데이터를 내려주는 것과 다르게 각 키들은 각자 자신만의 특별한 shard에 들어가게 된다.
어떤 상황에서 쓸지#
해당 방법은 shard key가 낮은 cardinality를 가질 때 좋은 선택이다. hash 함수를 거치지 않기 때문에 key based sharding과도 다르다. 그저 lookup table에서 key를 보고 어디에 데이터를 쓸지 결정하는 것 뿐이다.
장점#
유연성(flexibility)이다. range based sharding은 범위에 국한되고, key based sharding은 만들고 난 뒤 바꾸기 매우 어려운 hash 함수에 국한된다. 반면 directory based sharding은 데이터를 쪼개기 위한 entry들은 어떤 시스템이나 알고리즘에 상관 없이 entry를 할당할 수 있도록 해준다. 동적으로 shard를 추가하는 것도 비교적 쉽다.
단점#
반면 쿼리하거나 write하기 전에 lookup table에 연결이 필요하기 때문에, application 퍼포먼스에 안 좋은 영향(detrimental impact)을 줄 수 있다. 게다가 lookup table은 실패 지점이 될 수 있다. lookup table이 손상되면 데이터를 새로 쓰거나 존재하는 데이터에 접근하는 것에 영향을 줄 수 있기 때문이다.